Textsammlung mit Python und Meilisearch durchsuchbar machen
Gepostet am 03. Januar 2023 • 7 Minuten • 1376 Wörter • Andere Sprachen: English
Ziel des Artikels ist es, eine einfache Methode vorzustellen, eine größere Textsammlung aus PDFs durchsuchbar zu machen. Das dürfte für all diejenigen, interessant sein, die in der Wissenschaft arbeiten oder aus anderen Gründen eine umfangreiche Textsammlung besitzen (Bibliophile, Rollenspielerinnen, Jäger und Sammlerinnen).
Vor Jahren habe ich bereits einen ähnlichen Artikel geschrieben, der die Suche in einer großen Textsammlung via Tika und Solr behandelt. Beide Softwarekomponenten sind Projekte der Apache Foundation und damit Open Source. Beide basieren (wie bei vielen Apache Projekten) auf Java.
Inzwischen sind diverse Herausforderer am Horizont gesichtet worden, Zeit für einen neuen Artikel! Java ist zwar immer noch eine der großen Sprachen, ich habe jedoch seit einigen Jahren den Eindruck, dass die coolen neuen Projekte lieber andere Sprachen wie Rust oder Go bevorzugen. Die Gründe liegen auf der Hand: Java benötigt eine Runtime, die man gegebenenfalls erst installieren muss. Außerdem hat Java den Ruf, etwas behäbig zu sein. Das stimmt in Teilen, denn Java ist im Verhältnis relativ speicherhungrig und das erstmalige Starten von Programmen dauert durch das Laden der Runtime und die damit verbundene Initialisierung etwas länger als in Maschinencode kompilierte Software.
Daher soll der altehrwürdige Solr durch Meilisearch ersetzt werden. Meilisearch ist in Rust geschrieben und daher schnell, klein und für unseren Anwendungsfall ideal. Außerdem bringt es eine schicke Oberfläche für die Suche mit.
Meilisearch starten
Meilisearch kann auf verschiedene Weise gestartet werden. Wer Podman oder Docker verwendet, kann dies einfach durch den Start eines Containers erledigen:
# Docker
docker volume create meilisearch
docker run -it --rm -p 7700:7700 \
-v meilisearch:/meili_data docker.io/getmeili/meilisearch meilisearch --env="development"
# Podman
podman volume create meilisearch
podman run -it --rm -p 7700:7700 \
-v meilisearch:/meili_data docker.io/getmeili/meilisearch meilisearch --env="development"
Ich verwende eine Volume für das Speichern der Daten, dann gehen diese beim erneuten Start des Containers nicht
verloren (beachte den --rm-Parameter!). Alternativ kann man sich für sein eigenes Betriebssystem Meilisearch
herunterladen. Das geht direkt über Github
. Die Datei kann dann
ausgeführt werden, am besten auf der Kommandozeile:
# Unix
chmod +x meilisearch-*
./meilisearch-*
# Windows
meilisearch-windows-amd64.exe
Bei der nicht-Container-Variante werden mehrere Verzeichnisse erstellt.
Dokumente indexieren mit Python
Wir müssen nun einen Weg finden, den Text aus den Dokumenten zu extrahieren und an Meilisearch weiterzugeben. Einfach geht das mithilfe von Python. Wer mag, kann die folgenden Zeilen auch in ein Jupyter Notebook eingeben und ausführen.
Zunächst benötigen wir allerdings einige Python-Module:
PyMuPDFzum extrahieren von Text aus PDFmeilisearchfür die einfache Interaktion mit Meilisearch
Die meisten Python-Umgebungen unterstützen pip. Für Conda oder easyinstall einfach das Internet konsultieren:
pip install PyMuPDF meilisearch
# oder
pip3 install PyMuPDF meilisearch
# oder
pip3.exe install PyMuPDF meilisearch
Bizarrerweise muss PyMuPDF als fitz importiert werden – das nur zur Information.
Ein erster Test
Zunächst testen wir PyMuPDF anhand eines einfachen Beispiels. Nehmen wir eine beliebige PDF-Datei:
import fitz
pdf = fitz.open('/pfad/zur/pdfdatei.pdf')
for pg in range(pdf.page_count):
page = pdf[pg]
page_lines = page.get_text().splitlines()
print(page_lines)
Dieses kurze Skript nimmt eine PDF-Datei (Pfad bitte korrekt eingeben!) und extrahiert den Text:

Das Skript zur Indexierung
Auf dieser Grundlage können wir aufbauen. Schreiben wir ein Python-Skript, welches uns die Arbeit abnimmt! Ich halte
das Skript absichtlich sehr einfach. Wer mag, kann beispielsweise argparse verwenden, um den Pfad aus den übergebenen
Kommandozeilenparametern zu lesen.
Zunächst importieren wir die Module:
import fitz
import meilisearch
import os
import re
Jetzt definieren wir das Basisverzeichnis, das wir einlesen wollen. Unterhalb dieses Verzeichnisses werden alle PDF-Dateien eingelesen:
# Verzeichnis - bitte anpassen!
mydir = '/mein/verzeichnis'
# Windowsbenutzer bitte 'C:/mein/verzeichnis' eintragen...
Im Anschluss öffnen wir eine Verbindung zu Meilisearch:
# Meilisearch client öffnen
client = meilisearch.Client('http://localhost:7700')
myindex = client.index('textsammlung')
myindex.delete()
# Text nicht zeigen!
myindex.update_displayed_attributes([
'filename',
'full_path',
])
Hier definieren wir einen Index mit dem Namen textsammlung. Außerdem schränken wir die Anzeige der Felder ein, was im Browser auf jeden Fall eine gute Idee ist!
Nun kommt die eigentliche Hauptarbeit:
# Verzeichnis durchlaufen
uid = 1
for root, dirs, files in os.walk(mydir):
for file in files:
# nur PDFs sind interessant:
if file.lower().endswith('pdf'):
full_path = os.path.join(root, file)
sub_path = full_path[len(mydir):]
print("Erstelle Index für", sub_path)
# Text extrahieren
try:
pdf = fitz.open(full_path)
text = []
for pg in range(pdf.page_count):
page = pdf[pg]
# Text der Seite:
page_text = page.get_text()
# Schöner machen und anhängen an Gesamttext:
page_text = re.sub(r"-\n([a-zäöüß])", "\\1", page_text).replace("\n", " ").strip()
text.append(page_text)
# In Meilisearch einfügen:
myindex.add_documents([{
'uid': uid,
'filename': file,
'full_path': full_path,
'text': text
}])
uid += 1
except:
print('Fehler in Datei', sub_path)
Was passiert hier? Wir durchlaufen alle Unterverzeichnisse von mydir und filtern die PDF-Dateien heraus. Danach
extrahieren wir den Text mit PyMuPDF/fitz pro Seite. Da PDF die Texte in der Regel kaputt macht1, versuchen wir die
größten Unschönheiten zu kitten. Dazu klebe ich getrennte Wörter wieder zusammen (mit dem regulären Ausdruck), entferne
die Umbrüche und Leerzeichen. Übrig bleiben sollte eine einigermaßen saubere Textseite. Diese können wir nun in
Meilisearch einfügen.
Wenn alles passt, dann sollte der Aufruf von http://localhost:7700/ uns die Option der Textsammlung geben und auch die Möglichkeit, diese zu durchsuchen:

Etwas blöd ist hier allerdings, dass keine gefundenen Textstellen angezeigt werden. Schade eigentlich, das wäre ganz
praktisch! Man kann zum Testen oben mal die Zeilen mit myindex.update_displayed_attributes weglassen und sehen, wie
bei größeren Treffermengen der Browser in die Knie geht, weil er den Inhalt gesamter Bücher ausspuckt.
Suchen mit Python
Eine andere Lösung muss also her! Aber nachdem wir eh in Python arbeiten, können wir ja ganz einfach eine kleine Suche realisieren, nicht wahr? Ich poste hier mal das ganze Skript:
import re
import sys
import meilisearch
n = len(sys.argv)
if n == 1:
print("Mindestens einen Suchbegriff angeben, bitte!")
sys.exit(-1)
# Suchbegriff
search = ' '.join(sys.argv[1:])
# Meilisearch
client = meilisearch.Client('http://localhost:7700')
myindex = client.index('textsammlung')
myindex.update_displayed_attributes(['*'])
p = re.compile('<em>.*?</em>')
# Resultate und Highlights holen
results = myindex.search(search, {'attributesToRetrieve': ['*'], 'attributesToHighlight': ["text"]})
for result in results['hits']:
# Titel und Pfad ausgeben
print('\033[31m**** ' + result['filename'] + ' ****\033[39m')
print('=>', result['full_path'])
# Schauen, ob wir Treffer im Text haben:
if '_formatted' in result and 'text' in result['_formatted']:
print()
for i in range(len(result['_formatted']['text'])):
text = result['_formatted']['text'][i]
# Seite prüfen auf Treffer
if '<em>' in text:
# Mit Regex alle Treffer herausfiltern
iter = p.finditer(text)
for match in iter:
# Anfang und Ende bestimmen
start, end = match.span()
start -= 20
end += 20
if start < 0:
start = 0
if end > len(text):
end = len(text)
# Fragment ausgeben
print('[' + str(i+1) + ']: ' +
text[start:end].replace('<em>', '\033[36m').replace('</em>', '\033[39m') + '\033[39m')
print()
Das Skript erwartet einen oder mehrere Suchbegriffe und schickt sie als Suche an Meilisearch. Wir haben hier übrigens
den Index per myindex.update_displayed_attributes wieder so eingestellt, dass die Seiten mitkommen. Bei der Suche
geben wir noch Parameter mit: attributesToRetrieve gibt uns alle Felder zurück, attributesToHighlight erstellt ein
Highlight der gefundenen Textstellen.
Jetzt werden die Resultate schön ausgegeben. Ich verwende hier ANSI-Farben für den Terminal, wunderschön! Neben der
Datei und dem vollen Pfad wird geprüft, ob in den formatierten Textstellen (d.h. die mit Highlights) das <em>-Tag
vorkommt. Das ist ein Manko von Meilisearch: Man bekommt immer den gesamten Text zurück und muss sich die Schnipsel
selbst bauen. Und das machen wir per Regexp <em>.*?</em> (alles zwischen den Tags; das Fragezeichen steht für
non-greedy und bedeutet, dass die Suche maximal den nächsten Treffer mit einschließen soll). Wir bekommen Anfangs-
und Endpositionen mit, die wir etwas ausweiten (+/- 20 Zeichen maximal). Danach geben wir das Treffer-Schnipsel mit der
Seitenzahl des PDFs aus.
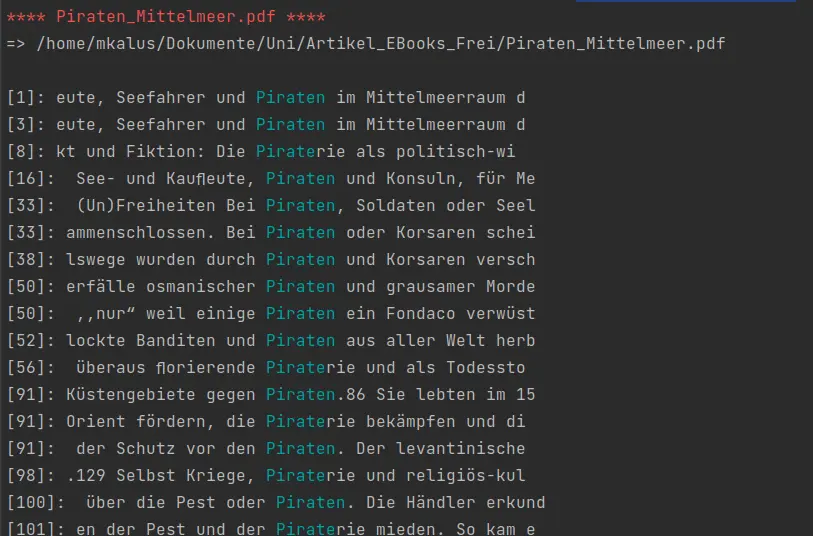
Führt man nun die Suche aus (z.B. mit python3 pdf_search.py piraten), bekommt man eine schöne Trefferliste samt
Seiten zurück:
Fazit
Man kann sich selbst mit einfachen Boardmitteln eine sehr mächtige PDF-Suchmaschine bauen. Meilisearch bietet hier eine sehr schöne Möglichkeit. Etwas unschön – zumindest in der aktuellen Version – ist das Fehlen einer Ausgabe für Treffer-Schnipsel. Das lässt sich mit Python einfach bauen. Folgende Verbesserungen sind denkbar – vielleicht werde ich sie in kommenden Blogartikeln behandeln:
- Webinterface für die Suche mit Schnippseln
- Einfacheres Indexieren von Dokumenten (per Web?)
- Indexieren von neuen Dateien
-
In meiner Masterarbeit in Informatik habe ich PDF hassen gelernt. Ich habe das Format analysiert und weiß nun, dass es ein kaputtes Scheißformat ist. An die Archivare dort draußen: Wenn Adobe euch erzählt, PDF eignet sich zur Langzeitarchivierung: Glaubt das nicht, es ist ein kaputtes Format. Andererseits: In zehn Jahren werden wir mithilfe von KI alte PDFs semantisch erschließen. Dafür gibt es bestimmt wieder jede Menge Drittmittel und Stellen… ↩︎