Make your Text Collection Searchable with Python and Meilisearch
Posted on January 3, 2023 • 8 minutes • 1515 words • Other languages: Deutsch
The goal of this article is to present a simple method to make a large collection of PDFs searchable. This should be of interest to those who work in the sciences or who have a large text collection for other reasons (bibliophiles, role players, hunters and collectors of written matter).
Years ago, I already wrote a similar article which dealt with searching in a large collection of text using Tika and Solr . Both software components are projects of the Apache Foundation and thus open source. Both (like many Apache projects) are based on Java.
Several challengers have been spotted on the horizon, so it’s time for a new article! While Java is still one of the major languages, in recent years, I have had the impression that the cool new projects prefer other languages like Rust or Go. The reasons are obvious: Java requires a runtime, which might have to be installed. Also, Java has the reputation of being somewhat sluggish. That’s true to an extent, as Java is relatively memory-hungry in comparison and initial startup of programs takes longer due to the loading of the runtime and its initialization compared to software compiled into machine code.
Therefore, the venerable Solr will be replaced by Meilisearch . Meilisearch is written in Rust, and is therefore fast, lightweight and ideal for our use case. It also brings a slick interface for searching.
Firing up Meilisearch
Meilisearch as a search engine can be started in different ways . For those of you using Podman or Docker, this is easy:
# Docker
docker volume create meilisearch
docker run -it --rm -p 7700:7700 \
-v meilisearch:/meili_data docker.io/getmeili/meilisearch meilisearch --env="development"
# Podman
podman volume create meilisearch
podman run -it --rm -p 7700:7700 \
-v meilisearch:/meili_data docker.io/getmeili/meilisearch meilisearch --env="development"
I am utilizing a volume to store the data, so it won’t be lost when the container is restarted (note the --rm
parameter!). Alternatively, you can download Meilisearch for your own operating system. You can do so directly from
Github
. The downloaded file can be run directly, preferably from
the command line:
# Unix
chmod +x meilisearch-*
./meilisearch-*
# Windows
meilisearch-windows-amd64.exe
In the non-containerized version, a few folders will be created in your current folder.
Indexing Documents with Python
We need to find a way to extract the text from the documents and pass it on to Meilisearch. The easy way is using Python. If you like, you can also enter and execute the following lines in a Jupyter Notebook.
First, however, we need some Python modules:
PyMuPDFto extract text from PDFsmeilisearchto interface with Meilisearch
Most python environments support pip, but you can also use Conda or easyinstall (i.e. search the Internet):
pip install PyMuPDF meilisearch
# or
pip3 install PyMuPDF meilisearch
# or
pip3.exe install PyMuPDF meilisearch
Strangely, PyMuPDF needs to be imported as fitz. Feel informed about this peculiarity!
An Initial Test
First, we test PyMuPDF using a simple example. Let’s take any PDF file:
import fitz
pdf = fitz.open('/path/to/pdffile.pdf')
for pg in range(pdf.page_count):
page = pdf[pg]
page_lines = page.get_text().splitlines()
print(page_lines)
This short script takes a PDF file (please enter the path correctly!) and extracts the text:

The Indexing Script
Based on this, we can build our little program. Let’s write a Python script! I have kept the script very simple by
intention. Anyone who wants can use argparse’ for example to read the path from the passed command line parameters.
First, let’s import the modules:
import fitz
import meilisearch
import os
import re
Now we define the base directory we want to read in. All PDF files will be read in below this directory:
# Folder - please change!
mydir = '/my/folder'
# Windows users, please enter: 'C://my/folder'
Afterwards, we open a connection to Meilisearch:
# Open Meilisearch client
client = meilisearch.Client('http://localhost:7700')
myindex = client.index('textcol')
myindex.delete()
# Do not show text in browser!
myindex.update_displayed_attributes([
'filename',
'full_path',
])
We define an index named textcol. Moreover, we want to restrict the display fields, which is a good idea in the browser. Otherwise our output will be a bit sluggish on long result texts.
Finally, we do the bulk of the work:
# Traverse directories
uid = 1
for root, dirs, files in os.walk(mydir):
for file in files:
# we are only interested in PDFs
if file.lower().endswith('pdf'):
full_path = os.path.join(root, file)
sub_path = full_path[len(mydir):]
print("Creating index for", sub_path)
# Extract text
try:
pdf = fitz.open(full_path)
text = []
for pg in range(pdf.page_count):
page = pdf[pg]
# Text der Seite:
page_text = page.get_text()
# Make text nicer and append to text array
page_text = re.sub(r"-\n([a-zäöüß])", "\\1", page_text).replace("\n", " ").strip()
text.append(page_text)
# Add to Meilisearch:
myindex.add_documents([{
'uid': uid,
'filename': file,
'full_path': full_path,
'text': text
}])
uid += 1
except:
print('Error in file', sub_path)
What is happening here? We are looping through all the subdirectories of mydir and filtering out the PDF files. During
this run, we extract the text with PyMuPDF/fitz for each page. Since PDF usually messes up the text1, we try to
patch up the biggest unsightliness. To do this, I glue together separate words (with the regular expression), remove
the line breaks and spaces. What should remain is a somewhat clean text page. We can now insert this into Meilisearch.
If everything is working properly, the call from http://localhost:7700/ should give us the option of the textcol and also the possibility to search it:

Nice, but still not perfect. I would like to see the text snippets and pages. You can test by omitting the lines above
starting with myindex.update_displayed_attributes and see how the browser collapses with larger result sets when it
spits out the contents of entire books.
Search with Python
We need a different approach! Since we have been using Python, why not create a search script? Not so hard, actually, as you can see here:
import re
import sys
import meilisearch
n = len(sys.argv)
if n == 1:
print("Please, add at least one search term!")
sys.exit(-1)
# Search term(s)
search = ' '.join(sys.argv[1:])
# Meilisearch
client = meilisearch.Client('http://localhost:7700')
myindex = client.index('textcol')
myindex.update_displayed_attributes(['*'])
p = re.compile('<em>.*?</em>')
# Fetch results and highlights
results = myindex.search(search, {'attributesToRetrieve': ['*'], 'attributesToHighlight': ["text"]})
for result in results['hits']:
# Print title and full path
print('\033[31m**** ' + result['filename'] + ' ****\033[39m')
print('=>', result['full_path'])
# Check for hits within the text
if '_formatted' in result and 'text' in result['_formatted']:
print()
for i in range(len(result['_formatted']['text'])):
text = result['_formatted']['text'][i]
# Check page for highlight
if '<em>' in text:
# Filter out all hits using regexp
iter = p.finditer(text)
for match in iter:
# Determine start and end
start, end = match.span()
start -= 20
end += 20
if start < 0:
start = 0
if end > len(text):
end = len(text)
# Print fragment
print('[' + str(i+1) + ']: ' +
text[start:end].replace('<em>', '\033[36m').replace('</em>', '\033[39m') + '\033[39m')
print()
The script expects one or more search terms and sends them as a search to Meilisearch. To make our search work properly,
we reset the index option to show all fields (myindex.update_displayed_attributes). We also provide some parameters
to the search engine: AttributesToRetrieve returns all fields, attributesToHighlight creates a highlight structure
of the text passages.
Now we can print our results nicely. I’m using ANSI colors for the terminal here, very beautiful! In addition to the
file and the full path, the scripts checks whether the <em> tag occurs in the formatted texts (i.e. those with
highlights). This is to circumvent a drawback of Meilisearch: You always get the full text back from the server and
have to build the snippets yourself. And we do so using the regexp <em>.*?</em> (meaning: everything between the tags;
the question mark stands for non-greedy and means that the search should include the next hit at most). We retrieve
the start and end positions of the snippets that extend those a little (+/- 20 characters maximum). Finally, we print
the snippet including its page number within the PDF.
Running the script (e.g. python3 pdf_search.py pirates), we get a nice hit list including all pages:
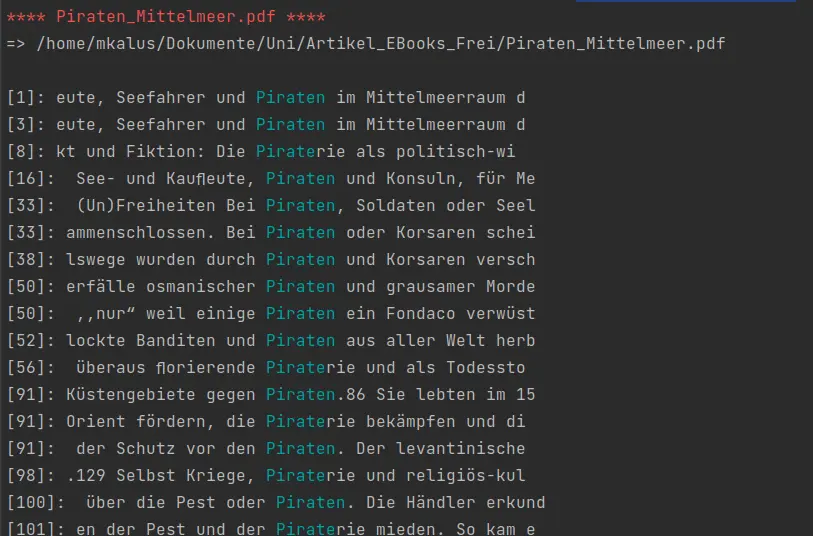
Conclusion
Using Open Source tools, you can build a very powerful PDF search engine. Meilisearch provides a pretty nice solution. Unfortunately - at least in the current version - it still lacks the ability to print snippets. So we can get back to Python on the command line. Several improvements could be implemented - maybe I will elaborate some of the following points in another blog post:
- Web interface for searching, including snippets
- Easier indexing of documents (using web browser?)
- Indexing of new files
-
In my master’s thesis in computer science, I have learned to hate PDFs. I analyzed the PDF format and I have come to the conclusion that it is a broken piece of crap. To all archivists out there: If Adobe tells you that PDF is suitable for long-term archiving, don’t believe them, it’s a broken shitty format. On the other hand, in ten years from now we will be able to semantically access old PDFs using AI. For that, there will certainly be plenty of third-party funds and positions, so if you want to keep your jobs as long as possible, use PDFs… ↩︎